一、ANRL [2018]
《ANRL: Attributed Network Representation Learning via Deep Neural Networks》
网络是对现实世界中复杂系统进行探索和建模的通用数据结构,包括社交网络、学术网络、万维网等等。在大数据时代,网络已经成为一个重要媒介,用于有效地存储、访问交互实体的关系知识(
relational knowledge) 。在网络中挖掘知识已经引起了学术界和工业界的持续关注,例如在线广告、推荐系统。大多数的这些任务都需要精心设计的模型,并且需要大量专家努力进行特征工程,而representation learning是自动化的feature representation方案。采用representation learning之后,可以通过在低维向量空间中学习从而极大地提升网络中的知识挖掘任务,如聚类、链接预测、分类等任务。network representation learning中的相关工作可以追溯到基于图的降维方法,例如局部线性嵌入(Locally Linear Embedding: LLE)、Laplacian Eigenmap: LE。LLE和LE都通过构建最近邻图(nearest neighbor graph)来维护数据空间中的局部结构(local structure)。为了使相互连接的节点在representation空间中彼此更接近,人们计算亲和图 (affinity graph)的相应eigenvector作为节点的representation。这些方法的一个主要问题是:由于计算eigenvector的计算复杂度太高,它们很难扩展到大型网络。受到
word2vec模型最近成功的启发,人们已经提出了许多基于网络结构的representation learning方法,并在各种application中显示出良好的性能。然而,节点属性信息没有受到太多关注,实际上这些节点属性信息可能在许多application中发挥重要作用。我们经常在现实世界的网络中观察到带各种属性的节点,这种网络被称作属性信息网络(attributed information network)。例如,在Facebook社交网络中,用户节点通常关联了个性化的用户画像,包括年龄、性别、教育、以及发帖内容。最近的一些努力通过整合网络拓扑信息和节点属性信息来探索属性信息网络,从而学到更好的representation。属性信息网络中的
representation learning仍然处于早期阶段,能力相当有限,原因是:网络拓扑和节点属性是两个异质的信息源,因此很难在公共向量空间中保存它们的属性。
观察到的网络数据往往是不完整的,甚至是噪音(
noisy)的,这使得更加难以获取有信息量的representation。
为了解决上述挑战,论文
《ANRL: Attributed Network Representation Learning via Deep Neural Networks》提出了一个统一的框架,称作ANRL。该框架通过联合地集成网络结构信息和节点属性信息来学习属性信息网络中的、鲁棒的representation。更具体而言,论文利用深度神经网络的强大表达能力来捕获两个信息源的、复杂的相关性,这两个信息源由邻域增强自编码器(neighbor enhancement autoencoder)、以及属性感知(attribute-aware)的SkipGram模型组成。总而言之,论文的主要贡献如下:论文提出了一个统一的框架
ANRL,它将网络结构邻近性(proximity)和节点属性亲和性(affinity)无缝集成到低维representation空间中。更具体而言,论文设计了一个邻域增强自编码器,它可以在representation空间中更好地保持数据样本之间的相似性。论文还提出了一个属性感知的SkipGram模型来捕获结构相关性。这两个组件与一个共享的编码器相连,其中这个共享编码器捕获了节点属性信息以及网络结构信息。论文通过两个任务(链接预测任务、节点分类任务)对六个数据集进行了广泛的实验,并通过实验证明了所提出模型的有效性。
相关工作:一些早期的工作和其它谱方法(
spectral method)旨在保留数据的局部几何结构,并在低维空间表达数据。这些方法是降维技术的一部分,可以被视为graph embedding的先驱。最近,
network representation learning在网络分析中越来越受欢迎。network representation learning专注于嵌入当前的网络而不是构建亲和图affinity graph。其中:DeepWalk执行截断的随机游走从而生成节点序列,并将节点序列视为sentence并输入到SkipGram模型从而学习representation。Node2vec通过采用广度优先(breadth-first: BFS)和深度优先(depth-first: DFS)的图搜索策略来探索不同的邻域,从而扩展了DeepWalk。LINE不是执行随机游走,而是优化一阶邻近性和二阶邻近性。GraRep提出为graph representation捕获k阶关系信息 (relational information)。SDNE将图结构整合到深度自编码器(deep autoencoder)中,从而保持高度非线性的一阶邻近性和二阶邻近性。
属性信息网络在许多领域中无处不在。通过同时使用网络结构信息和节点属性信息来实现更好的
representation,这是很有前景的。一些现有的算法已经研究了将这两个信息源联合地嵌入到一个统一空间中的可能性。例如:TADW将DeepWalk和相关的文本特征整合到矩阵分解框架中。PTE利用label信息和不同level的单词共现信息来生成predictive text representation。TriDNR使用来自三方的信息(包括节点结构、节点内容、节点label)来联合学习node representation。
尽管上述方法确实将节点属性信息融合到
representation中,但它们是专门为文本数据设计的,不适用于许多其他类型的特征(如连续数值特征)。最近,人们已经提出了几种特征类型无关的
representation learning算法,以通过无监督或半监督的方式进一步提高性能。这些算法可以处理各种特征类型,并捕获结构邻近性(structural proximity) 以及属性亲和性(attribute affinity)。AANE是一种分布式embedding方法,它通过分解属性亲和矩阵,并使用network lasso正则化来惩罚互相连接的节点之间的embedding difference,从而联合地学习node representation。Planetoid同时开发了transductive方法和inductive方法来联合预测图中的class label和邻域上下文。SNE通过利用端到端神经网络模型来捕获网络结构信息和节点属性信息之间复杂的相互关系,从而生成embedding。另一个半监督学习框架
SEANO采用输入样本属性、以及它平均邻域属性聚合的方式,从而缓解异常值在representation leraning过程中的负面影响。
也有一些工作在探索异质信息网络中的
representation learning。metapath2vec利用基于metapath的随机游走来生成异质节点序列,并采用异质SkipGram模型来学习node representation。《Attributed network embedding for learning in a dynamic environment》提出了一种模型,该模型可以在动态环境而不是静态网络中处理representation learning。《Attributed signed network embedding》研究了有符号信息网络中的representation learning问题。
我们将这些可能的扩展保留为未来的工作。
1.1 模型
令
属性信息网络的
representation learning任务的目标是:学习一个映射函数network structure proximity)、节点属性邻近关系 (node attribute proximity)。
1.1.1 邻域增强自编码器
为了编码节点的属性信息,我们设计了一个邻域增强自编码器模型。该自编码器由编码器和解码器组成,旨在重建目标节点的邻域而不是目标节点本身。值得注意的是,当我们的目标邻域是输入节点本身时,该自编码器退化为传统的自编码器。
具体而言,对于节点
target neighbor)的聚合函数为定义每一层的隐向量为:
其中:
ReLU),我们的目标是最小化自编码器的损失:
其中:
函数
邻域加权平均 (
Weighted Average Neighbor):其中:
邻域的逐元素中位数(
Elementwise Median Neighbor):其中
中位数指的是排序之后位于正中间的那个数。
与传统的自编码器相比,我们的邻域增强自编码器在保持节点之间的邻近性方面效果更好。因为邻域增强自编码器迫使节点重建相似的目标邻域,从而使得位置相近的节点具有相似的
representation。因此,它捕获了节点属性信息和局部网络结构信息。另外,重建的目标综合了多个邻域节点的信息,这比传统的重建单个节点(目标节点自身)更为鲁棒。因为单个节点的波动更大。
最后,我们提出的邻域增强自编码器是一个通用框架,可用于各种自编码器的变体,如降噪自编码器、变分自编码器。
1.1.2 属性感知 SkipGram 模型
属性感知
SkipGram模型将属性信息融合到SkipGram模型。具体而言,在SkipGram的目标函数中为随机游走上下文提供当前节点的属性信息:其中:
其中:
CNN编码器、针对序列数据的RNN编码器。这里我们使用邻域增强自编码器(见小面的小节)。representation。
因此,
直接优化
其中:
sigmoid函数。degree。
1.1.3 ANRL 模型
ARNL模型同时利用了网络结构和节点属性信息。如下图所示,ANRL模型由两个耦合的模块组成:邻域增强自编码器模块、属性感知SkipGram模块。编码器将输入的属性信息映射到低维向量空间,并扩展出两路输出:
左路输出为邻域增强自编码器的解码器部分。
右路输出用于预测属性感知
SkipGram的节点上下文。
邻域增强自编码器、属性感知
SkipGram共享网络的前几层(编码器部分),因此这两个模块相互耦合。通过这种方式,ARNL学到的节点representationANRL可以视为多任务模型,包括:基于邻域增强自编码器的邻域属性重建任务、基于属性感知SkipGram的上下文预测任务。二者共享节点的representation。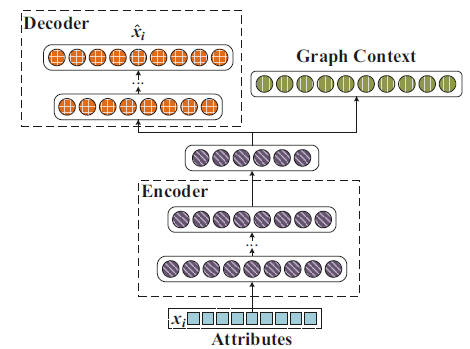
ANRL模型通过联合学习邻域增强自编码器模块、属性感知SkipGram模块两个模块,其目标函数为:其中:
representation。
通过这种方式,
ANRL将节点属性、局部网络结构、全局网络结构保留在一个统一的框架中。通过邻域增强自编码器模块捕获网络局部结构信息,通过属性感知的
SkipGram模块捕获网络全局结构信息,通过这两个模块同时捕获节点属性信息。值得注意的是:属性感知的
SkipGram模块的函数representation此外,为简单起见,我们使用单个非线性层来捕获图的上下文信息,并可以轻松地扩展到多个非线性层。
我们使用随机梯度算法来优化
ANRL训练算法:输入:
属性信息网络
每个节点开始的随机游走序列数量
随机游走序列长度
上下文窗口大小
embedding维度损失函数平衡系数
输出:节点的
representation矩阵算法步骤:
对每个节点执行
从随机游走序列中构建每个节点的上下文集合
根据函数
随机初始化所有的参数
迭代直到模型收敛,迭代步骤为:
随机采样一个
mini-batch的节点及其上下文。计算梯度
计算梯度
SkipGram模块的参数。
返回
embedding矩阵。
1.2 实验
数据集:
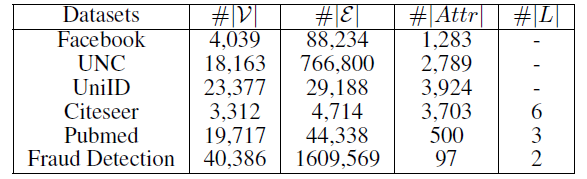
社交网络数据集:
Facebook和UNC数据集是两个典型的社交网络数据集,节点代表用户,边代表用户的好友关系。引文网络数据集:
Citeseer和Pubmed是典型的引文网络数据集,节点代表论文或出版物,边代表它们之间的引用关系。Citeseer中的论文分为六种类别:Agents,AI,DB,IR,ML,HCI。Pubmed中的论文分别三种类别:Diabetes Mellitus Experimental、Diabetes Mellitus Type 1(I型糖尿病)、Diabetes Mellitus Type 2(II型糖尿病)。
用户行为网络数据集:
UniID和Fraud Detection是阿里巴巴提供的两个真实的用户行为数据集。UniID网络中的节点表示物理设备的ID,边表示在同一个用户的行为记录中观察到两个ID同时出现。Fraud Detection网络中存在两种类型的节点:cookie节点(代表买家)、seller节点(代表卖家)。cookie节点包含了带属性的cookie信息。为了获得同质
cookie网络,我们采用如下方法将二部图映射为仅包含cookie节点的图:当且仅当两个cookie之间存在至少五个共同的seller节点时,连接这两个cookie节点。我们的目标是鉴别哪些cookie是可疑的。
Baseline模型:我们将当前SOTA的network representation learning方法划分为以下几组:仅属性的方法(
Attribute-only):仅考虑节点属性信息。这里我们选择SVM和自编码器作为baseline模型。仅结构的方法(
Structure-only):仅考虑网络结构信息。这里我们选择DeepWalk, node2vec, LINE, SDNE作为baseline模型。属性和结构的方法(
Attribute + Structure):同时考虑节点属性信息和网络结构信息。这里我们选择AANE, SNE, Planetoid-T,TriDNR, SEANO作为baseline模型。
最后我们还给出
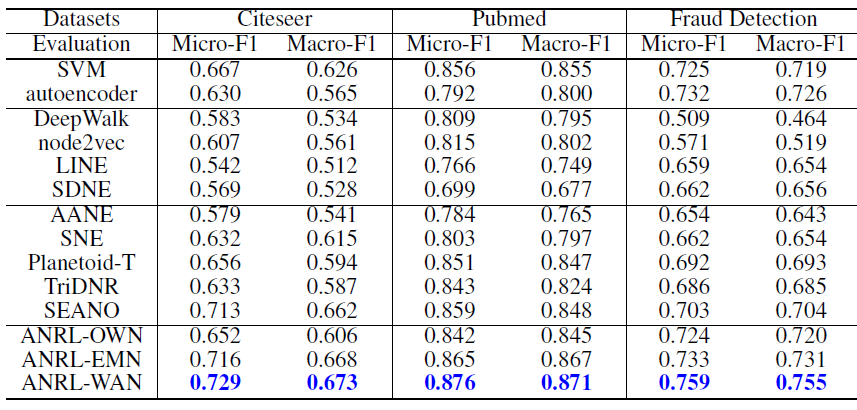
ANRL的几个变体:ANRL-WAN:使用Weighted Averate Neighbor来构造目标邻域。ANRL-EMN:使用Elementwise Media Neighbor来构造目标邻域。ANRL-OWN:采用传统的自编码器来重建节点自己,而不是重建目标邻域。
模型配置:
对于
baseline模型,我们使用原始作者发布的实现版本,并且baseline模型的参数已经调整为最优。在
Fraud Detection数据集中,我们选择将embedding维度设置为对于
LINE模型,我们将一阶representation和二阶representation拼接起来作为最终representation。对于
ANRL,我们选择随机游走序列长度为80、每个节点开始的随机游走序列数量为10、负采样比例为5、窗口大小为10。另外,
ANRL左路输出(包括了编码器和解码器)的层数和尺寸如下图所示,而右路输出仅使用单层神经网络。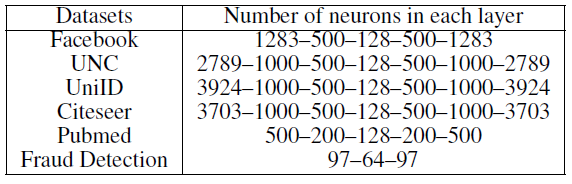
链接预测任务:我们通过链接预测任务来评估各种算法学到的
embedding的链接预测能力。我们随机移除图中
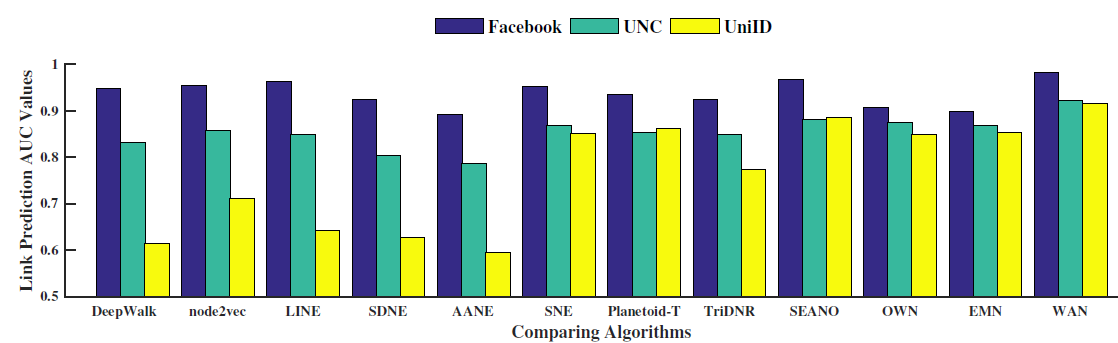
50%的链接,然后在移除后的图上训练节点embedding。一旦获得了节点embedding,我们将被移除的链接作为正样本,然后随机选择相同数量的、并不存在的链接作为负样本,从而构造测试集。我们在测试集上评估embedding的链接预测能力,具体做法是:根据余弦相似度对正样本和负样本进行排序。我们采用AUC来评估排序的质量,较高的AUC表示更好的性能。在三个无标签的数据集(
Facebook,UNC,UniID)上进行链接预测任务的效果如下图所示。结论:ANRL在所有数据集上都显著超越了baseline。由于
DeepWalk,node2vec,LINE,SDNE仅利用网络结构信息,因此当网络极为稀疏时(如UniID数据集),它们的性能相对较差。有趣的是,在这一组四个模型中,
node2vec取得了最好的结果。主要是因为node2vec可以通过有偏的随机游走探索各种网络结构信息。与之前的研究结果一致:我们观察到结合节点属性和网络结构信息可以提高链接预测性能,这反映了属性信息的价值。
其中,
AANE,TriDNR仅利用一阶网络结构信息,它们无法捕获足够的信息来进行链接预测。而该组其余算法通过在网络上执行随机游走从而捕获更高阶的网络邻近信息从而获得更好的性能。ARNL同时利用了节点属性信息(通过邻域增强自编码器和属性感知SkipGram模型)、全局结构信息(通过属性感知SkipGram模型)、局部结构信息(通过邻域增强自编码器)。我们认为性能提升的主要原因之一是ANRL同时考虑了局部结构信息和全局结构信息。
节点分类:我们通过分类预测任务来评估各种算法学到的
embedding的分类预测能力。我们从每个类别中随机选择
20个样本,并将它们作为标记数据(剩余所有节点在训练embedding过程中label信息不可用)来训练半监督baseline。在学到节点embedding之后,我们随机选择30%的节点来训练SVM分类器,剩余节点作为测试集用于评估性能。我们重复该过程10次,并报告测试集上的平均Macro-F1和平均Micro-F1。实验结果如下。结论:ANRL-WAN在所有数据集中超越了所有baseline方法,其它基于属性和结构的方法紧随其后,然后是基于结构的方法。这证明了属性信息的价值,对节点属性进行适当的建模可以带来更好的representation,并显著提高性能。attribute-only方法优于大多数structure-only方法。因为和节点属性相比,单纯的网络结构为分类任务提供的信息非常有限。另外,我们发现自编码器比
SVM稍差,这表明降维的过程中可能会丢失一部分有用的信息。SEANO通过在representation learning阶段聚合邻域的属性信息,超越了其它几种最新的Attribute + Structure方法。AANE在该组的表现不佳,原因是AANE涉及到亲和矩阵(affinity matrix)的分解操作。由于我们通常不知道每对节点之间的相似性,因此需要根据特定的相似性度量进行计算。这大大降低了AANE的性能。ANRL-WAN和ANRL-EMN的性能优于ANRL-OWN以及大多数其它baseline方法。ANRL-WAN明显优于ANRL-OWN,这证明了我们提出的邻域增强自编码器的有效性。此外,我们的属性感知SkipGram模块和邻域增强自编码器模块使得潜在representation更加平滑和鲁棒,这对于很多任务而言也是很重要的。